In The Eyes of Beholder
In the Eye of Beholder: Joint Learning of Gaze and Actions in First Person Video
21 June 2021
Authors: Yin Li, Miao Liu, James M. RehgURL: https://openaccess.thecvf.com/content_ECCV_2018/html/Yin_Li_In_the_Eye_ECCV_2018_paper.html
Comments: 2018 Proceedings of the European Conference on Computer Vision (ECCV)
Categories: attention, action-recognition, gaze-prediction, egocentric
What ?
Joint gaze estimation and action recognition using gaze distribution as attention. New dataset EGTEA (fine-grained actions) - 28hrs with 2D gaze labelling.
Why ?
Gaze is used for FPV action recognition since it naturally defined the ROI which can be used for attention based network. Gaze measurements are also quite in-consistent and causes uncertainty in modelling deep networks which is why instead of 2D gaze coordinates, a probabilistic distribution is preferred for modelling the deep network.
How ?
The authors use 2D gaze coordinates and transform it to a probabilistic distribution of gaze to create a saliency map for the image plane.
The saliency acts as an attention grid for the input frame(s), which is used to extract visual features from the image. - weighted average pooling. The extracted features are then fed to a classifier which predicts the action.
: empty_plane = np.zeros(m,n)
: empty_plane[x][y] = 1 ## gaze position
: q(m,n) = multivariate_normal(q(m,n)) ## probabilistic distribution , when no gaze is available, instead use a uniform distribution.
: g'(m,n) <- q(m,n) ## gaze attention map
: p(g|x) = g'(m,n)
: π = qψ(X) ## output from the neural network, distribution achieved by the network
: q(g|x) = π(m,n)
: p(y|g, x) = f (Σ(m,n) π(m,n) φ(x)(m,n) ) = SOFTMAX(W_t (Σ(m,n) π(m,n) φ(x)(m,n))
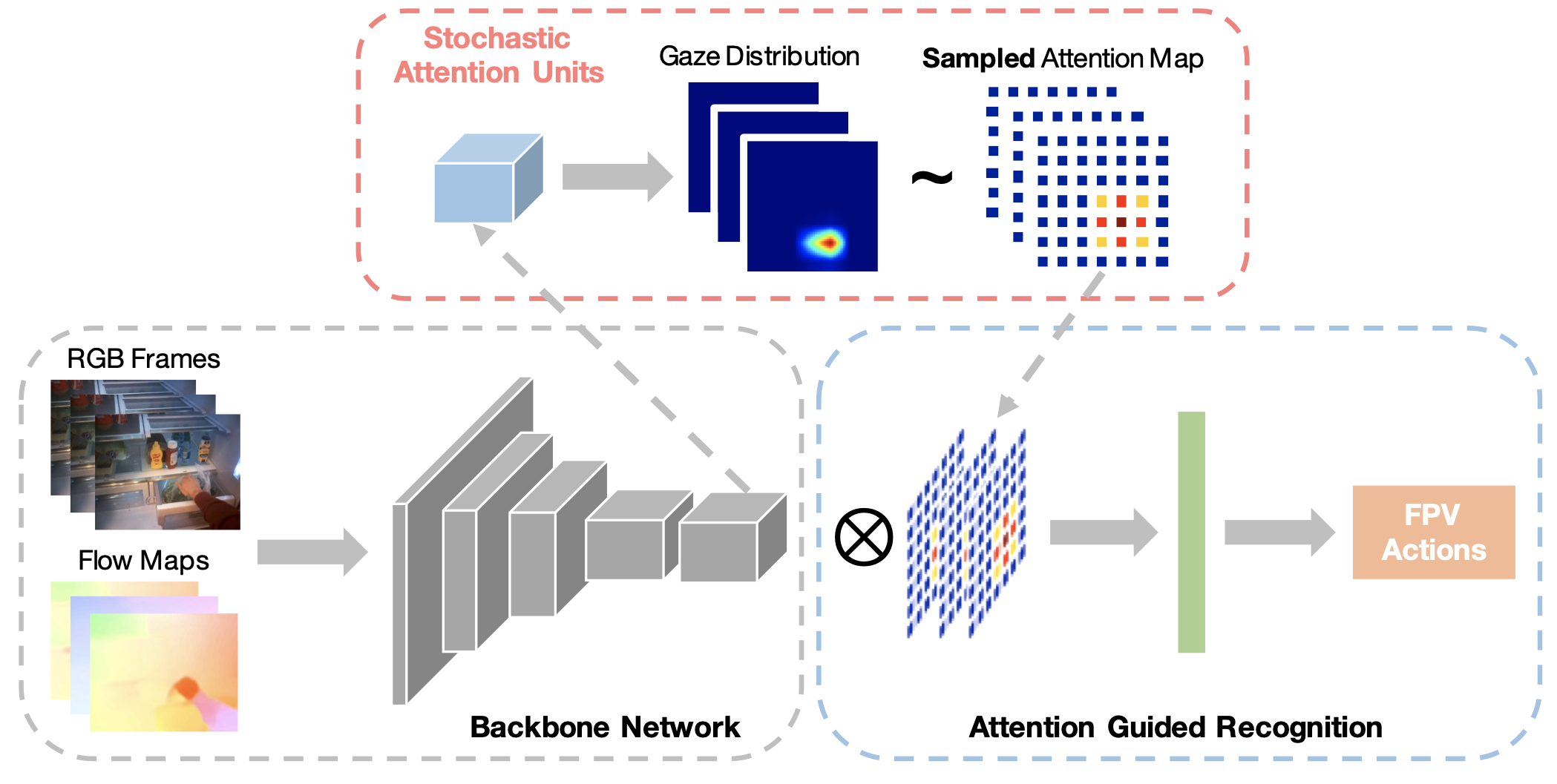
The sampling from π(m,n) is done using Gumbel-Softmax approach to make the entire pipeline fully differentiable instead of direct sampling.
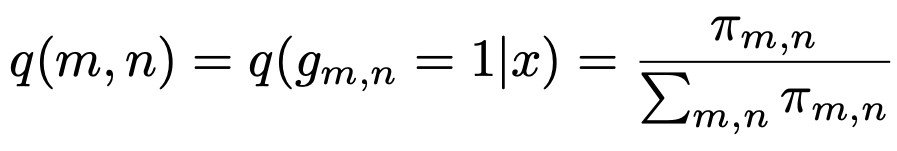
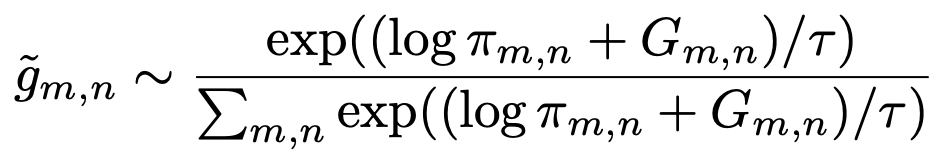
Since, the network has two main goals to achieve : Create accurate gaze distribution and predict correct action. Therefore, the loss function is the negative of empirical lower bound :
Loss : −Σ log(p(y|g,x)) + KL[q(g|x)||p(g|x)]
TL;DR Actions and Hand Mask Annotations.
Notes :
The action classification accuracy is best when combined with gaze probability / attention on EGTEA dataset. When trained and tested on Epic-Kitchen, it performs on par with SOTA but not better, given that EPIC-Kitchen does not have gaze labelling.
Comments
No comments found for this article.
Join the discussion for this article on this ticket. Comments appear on this page instantly.