TCN for action anticipation
Multi-Modal Temporal Convolutional Network for Anticipating Actions in Egocentric Videos
22 June 2021
Authors: Olga Zatsarynna, Yazan Abu Farha and Juergen GallURL: https://openaccess.thecvf.com/content/CVPR2021W/Precognition/html/Zatsarynna_Multi-Modal_Temporal_Convolutional_Network_for_Anticipating_Actions_in_Egocentric_Videos_CVPRW_2021_paper.html
Comments: 2021 Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
Categories: multi-modal, action-anticipation, egocentric
What ?
Multi Modal based action anticipation approach using temporal convolutional networks.
Why ?
Recurrent Network (LSTM) based network are not efficient with inference and causes latency.
How ?
Each clip is divided into ‘observed video’ and ‘action anticipation’ segment. The ‘observed’ segment is further split into smaller splits with single frame(RGB, object) and 5 frame(optical flow: horizontal and vertical component) for each snippet. For each modality (RGB, Optical flow and Object recognition) a uni-modal network is pre-trained using a hierarchy of dilated temporal convolution nets with residual blocks.
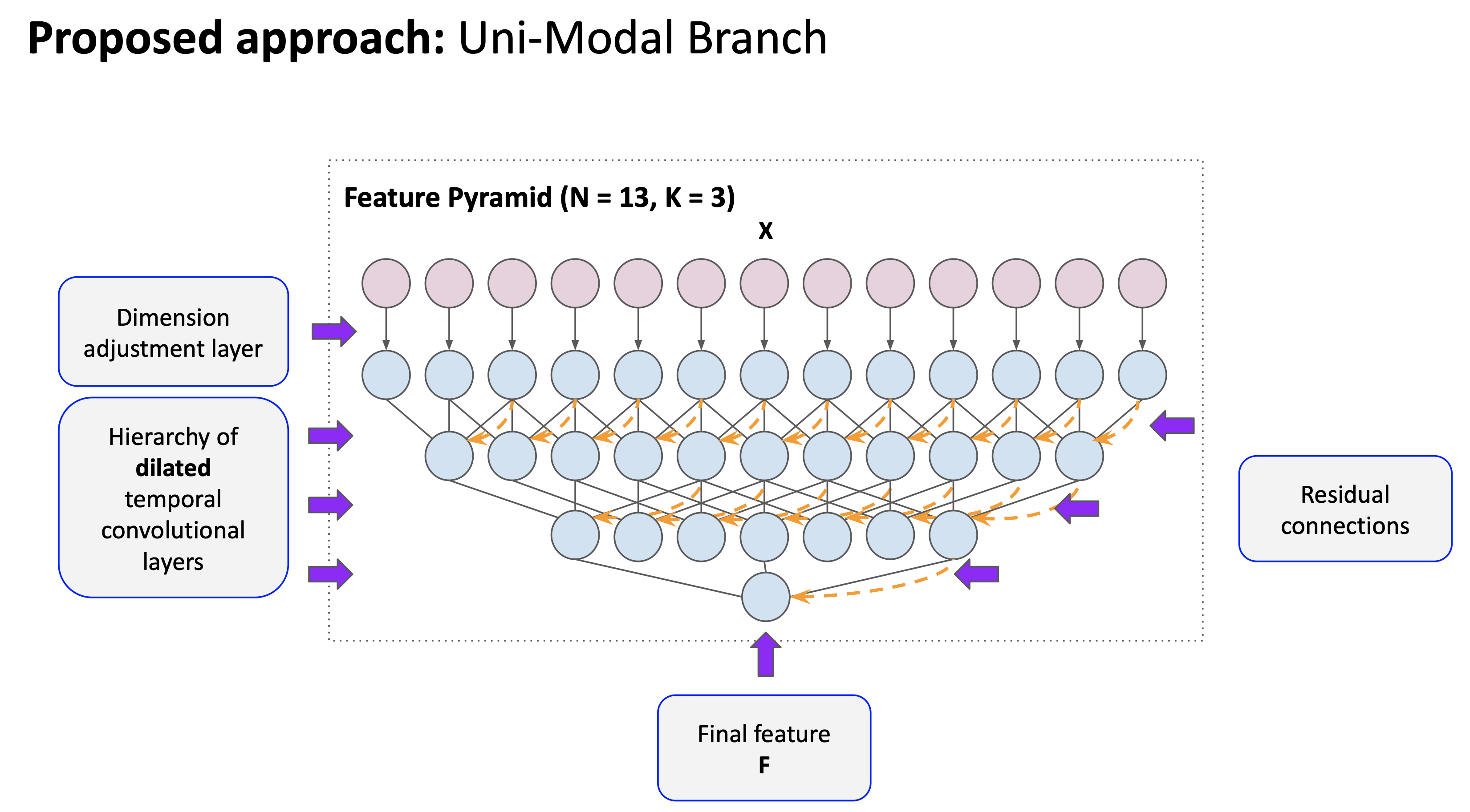
Backbone networks :
- RGB / Optical flow : TBN (Temporal Binding Network Kazakos et. al ICCV’19)
- Object recognition : Fast-CNN
Features from different modalities are fused together in a pair-wise and mutual embeddings.
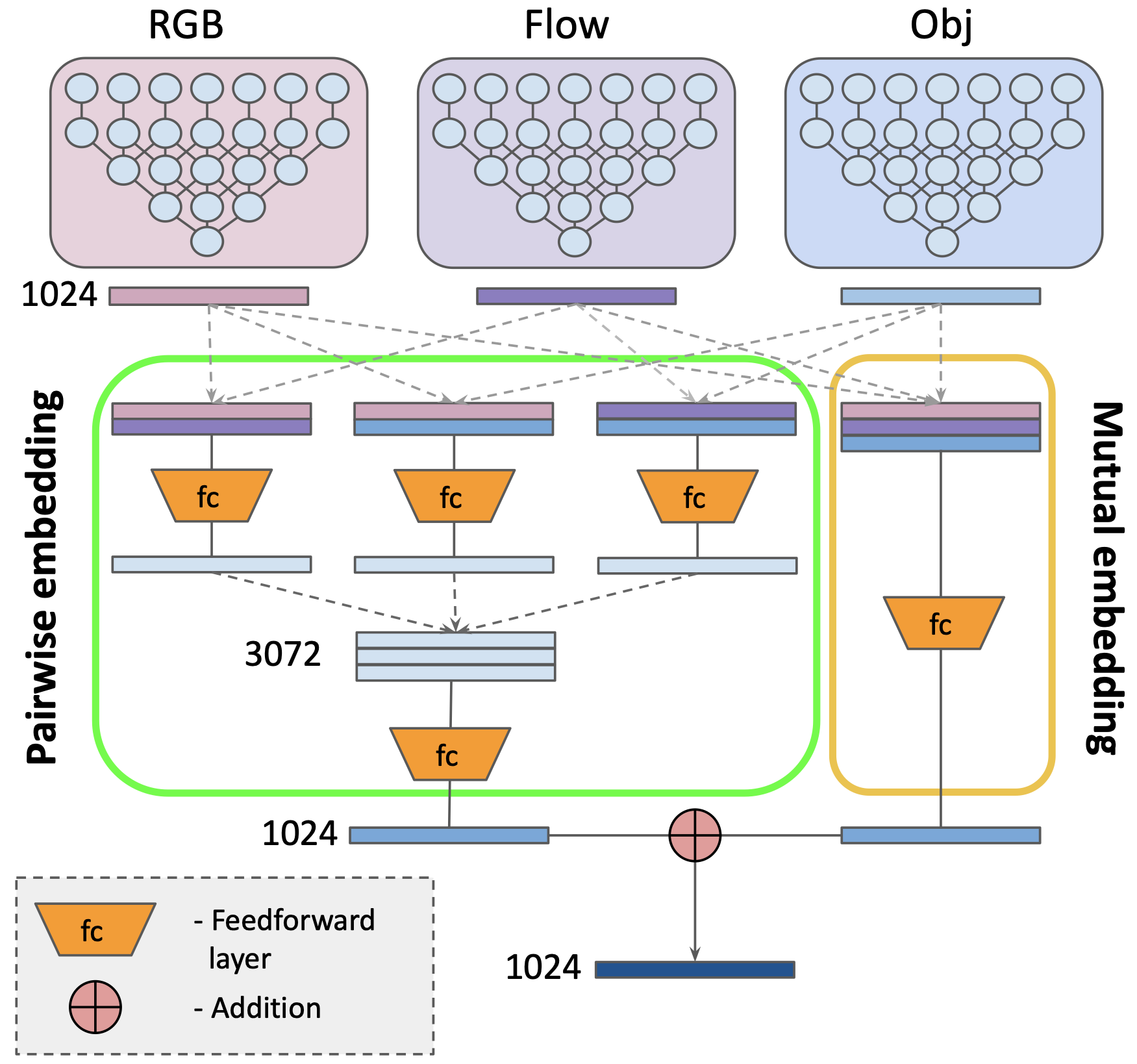
import numpy as np
rgb = np.random.randn(1024)
flow = np.random.randn(1024)
obj = np.random.rand(1024)
pair_rgb_obj = np.random.randn(rgb + obj)
pair_rgb_flow = np.random.randn(rgb + flow)
pair_obj_flow = np.random.randn(flow + obj)
pair = np.random.randn(pair_rgb_obj + pair_rgb_flow + pair_obj_flow)
mutual = np.random.randn(rgb + flow + obj)
final = mutual + pair
output = softmax(final)
Notes
Does not perform better than SOTA action anticipation methods. But has faster training and inference time wrt RNN based network.
Comments
No comments found for this article.
Join the discussion for this article on this ticket. Comments appear on this page instantly.