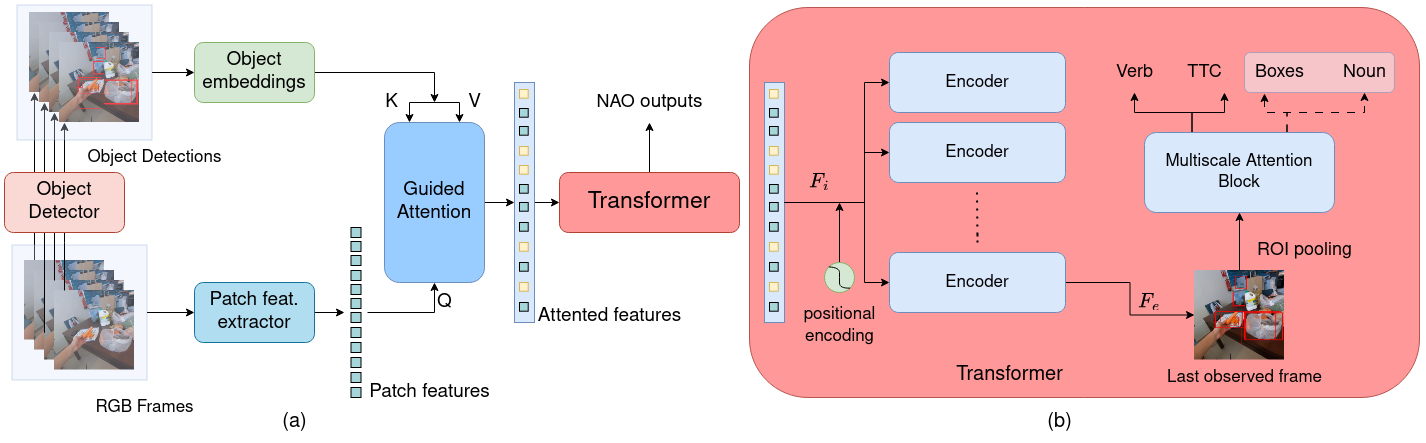
|
Short-term action anticipation (STA) in first-person videos is a challenging task that involves understanding
the next active object interactions and predicting future actions. Exist- ing action anticipation methods have
primarily focused on utilizing features extracted from video clips, but often over- looked the importance of objects
and their interactions. To this end, we propose a novel approach that applies a guided at- tention mechanism between
the objects, and the spatiotempo- ral features extracted from video clips, enhancing the motion and contextual
information, and further decoding the object- centric and motion-centric information to address the problem of STA
in egocentric videos. Our method, GANO (Guided Attention for Next active Objects) is a multi-modal, end-to- end, single
transformer-based network. The experimental re- sults performed on the largest egocentric dataset demonstrate that GANO
outperforms the existing state-of-the-art methods for the prediction of the next active object label, its bounding box
location, the corresponding future action, and the time to contact the object. The ablation study shows the positive
contribution of the guided attention mechanism compared to other fusion methods. Moreover, it is possible to improve
the next active object location and class label prediction results of GANO by just appending the learnable object tokens
with the region of interest embeddings.
|