|
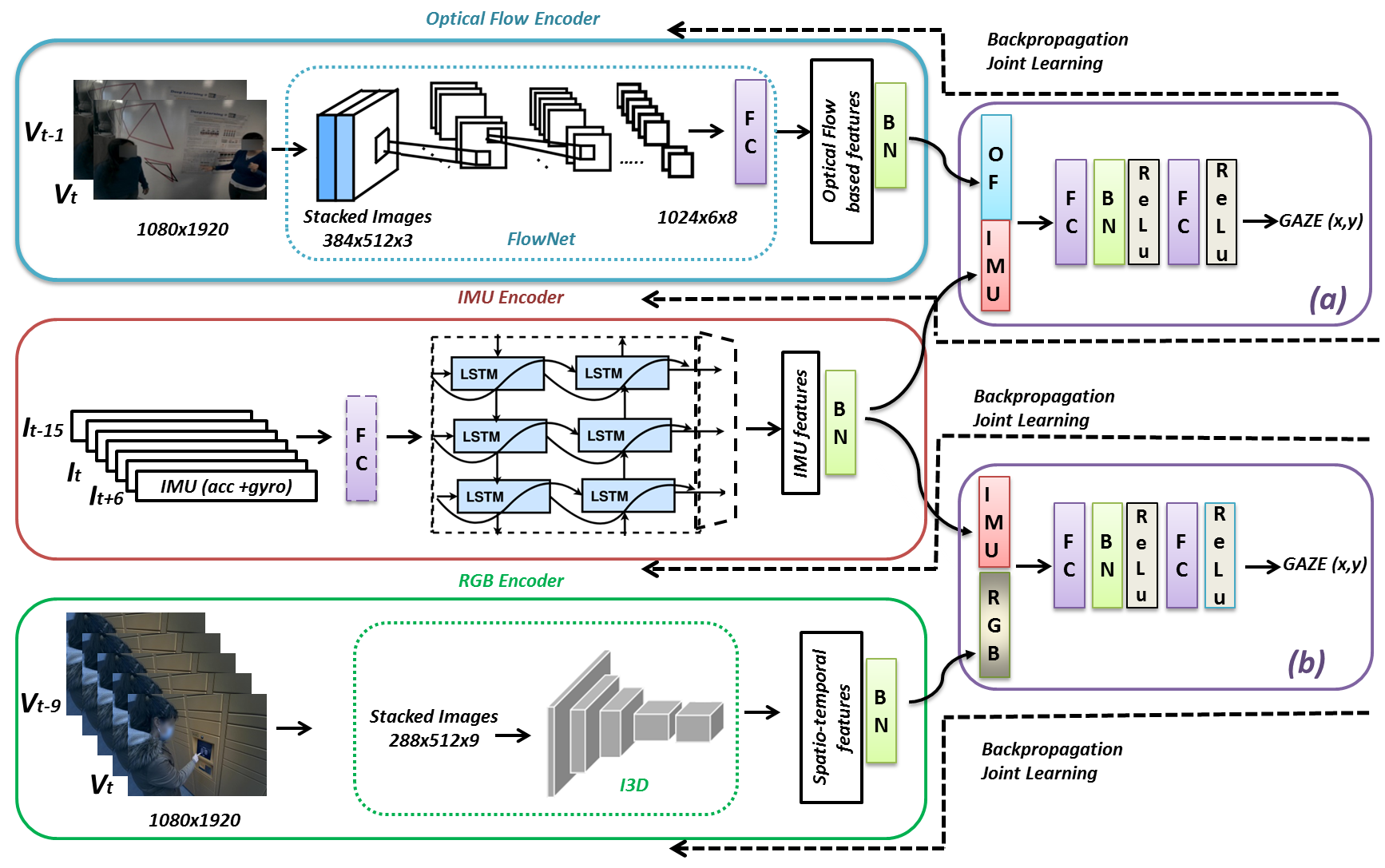
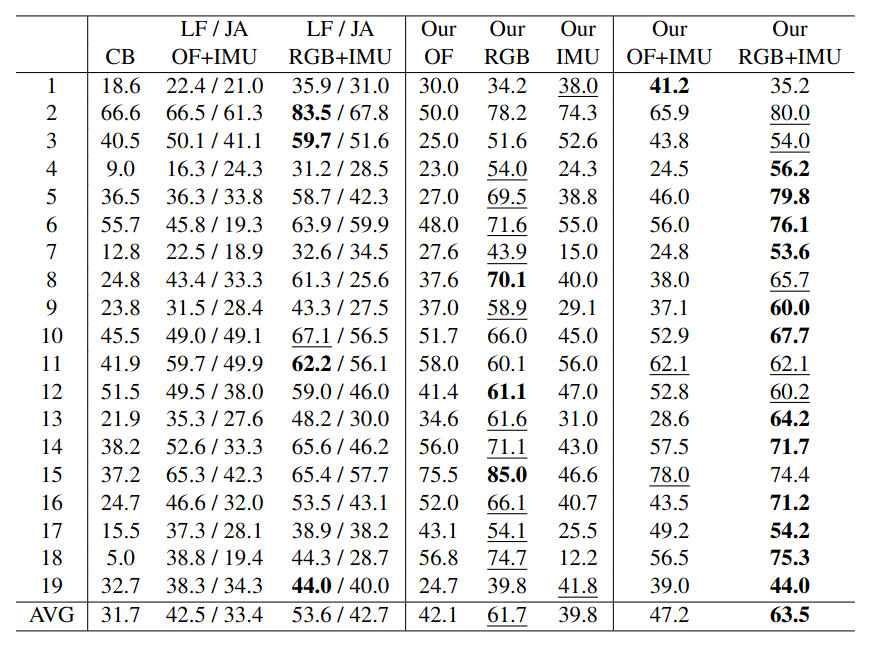
Gaze prediction in egocentric videos is a fairly new research topic, which might have several applications for assistive technology (e.g., supporting blind people in their daily interactions), security (e.g., attention tracking in risky work environments), education (e.g., augmented / mixed reality training simulators, immersive games) and so forth. Egocentric gaze is typically estimated from video while few works attempt to use inertial measurement unit (IMU) data, a sensor modality often available in wearable devices (e.g., augmented reality headsets). Instead, in this paper, we examine whether joint learning of egocentric video and corresponding IMU data can improve the first-person gaze prediction compared to using these modalities separately. In this respect, we propose a multimodal network and evaluate it on several unconstrained social interaction scenarios captured by a first-person perspective. The proposed multimodal network achieves better results compared to unimodal methods as well as several (multimodal) baselines, showing that using egocentric video together with IMU data can boost the first-person gaze estimation performance.
|