|
|
|
|
|
|
|
|
|
|
|
|
|
|
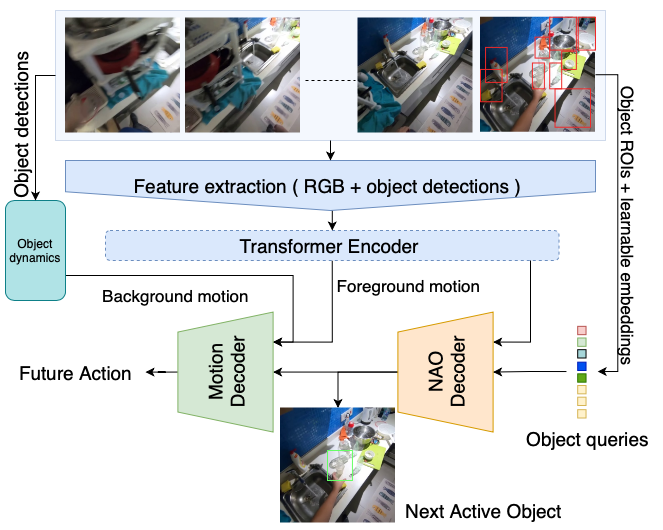
| Objects are crucial for understanding human-object interactions. By identifying the relevant objects, one can also predict potential future interactions or actions that may occur with these objects. In this paper, we study the problem of Short-Term Object interaction anticipation (STA) and propose NAOGAT (Next-Active-Object Guided Anticipation Transformer), a multi-modal end-to-end transformer network, that attends to objects in observed frames in order to anticipate the next-active-object (NAO) and, eventually, to guide the model to predict context-aware future actions. The task is challenging since it requires anticipating future action along with the object with which the action occurs and the time after which the interaction will begin, a.k.a. the time to contact (TTC). Compared to existing video modeling architectures for action anticipation, NAOGAT captures the relationship between objects and the global scene context in order to predict detections for the next active object and anticipate relevant future actions given these detections, leveraging the objects' dynamics to improve accuracy. One of the key strengths of our approach, in fact, is its ability to exploit the motion dynamics of objects within a given clip , which is often ignored by other models, and separately decoding the object-centric and motion-centric information. Through our experiments, we show that our model outperforms existing methods on two separate datasets, Ego4D and EpicKitchens-100 (``Unseen Set''), as measured by several additional metrics, such as time to contact, and next-active-object localization. |
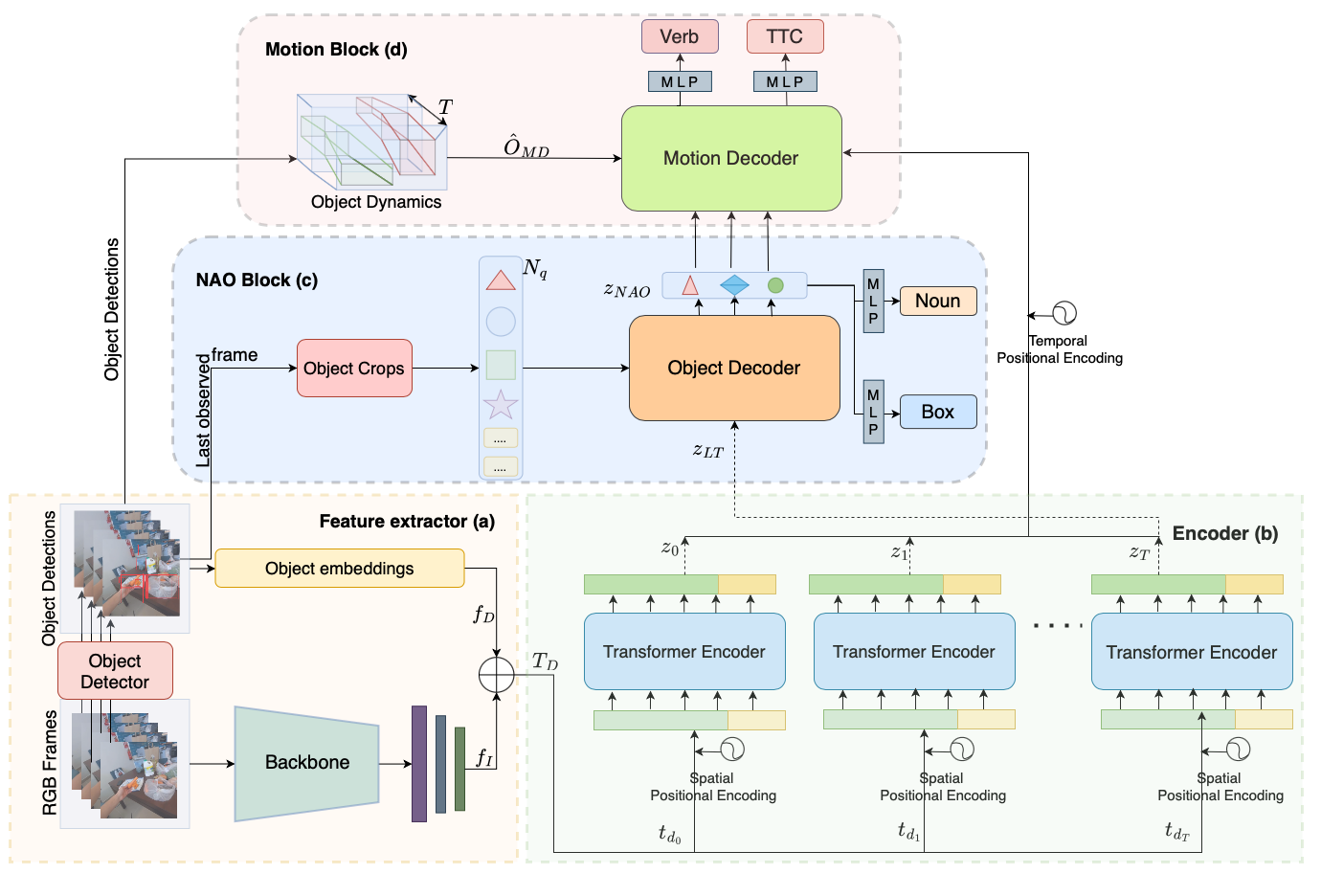 |
| Fig 2. Our NAOGAT model first extracts feature information and object detections from a set of frames within an observed clip segment by means of a backbone network and an object detector; object detections are then transformed into object embeddings using an MLP network. The frame features are then concatenated with object embeddings to be sent to the transformer encoder after appending with spatial positional encoding. The encoder then extracts foreground motion (video memory) and global context features, which are used in two separate decoders to perform object-centric and motion-centric predictions. For object decoder, detections from the last observed frame and learnable embeddings are used to create object queries to perform fixed-set predictions for the NAO class label and its bounding box using a transformer decoder. In the last stage, we leverage Object dynamics to extract background motion in terms of object trajectories for detected objetcs in sampled frames. We then use the object decoder's outputs with the combined frame representation of video memory and object dynamics to perform predictions for motion-related outputs, such as future action and time to contact (TTC). |
 |
S. Thakur, C. Beyan, P. Morerio, A. Del Bue, V. Murino, Leveraging Next-Active Objects for Context-Aware Anticipation in Egocentric Videos In Winter Conference on Applications of Computer Vision (WACV), 2023 (hosted on arxiv) Mail: sanket.thakur@iit.it for access to the next-active-object data for EK-100 for last observed frame. If using the dataset, also cite our ANACTO work [ANACTO BIBTEX] |
Acknowledgements |