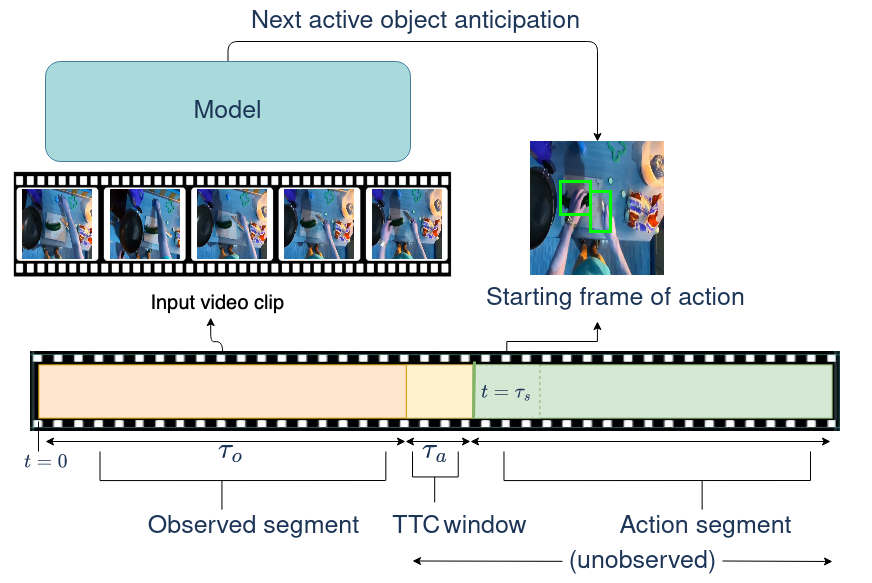
|
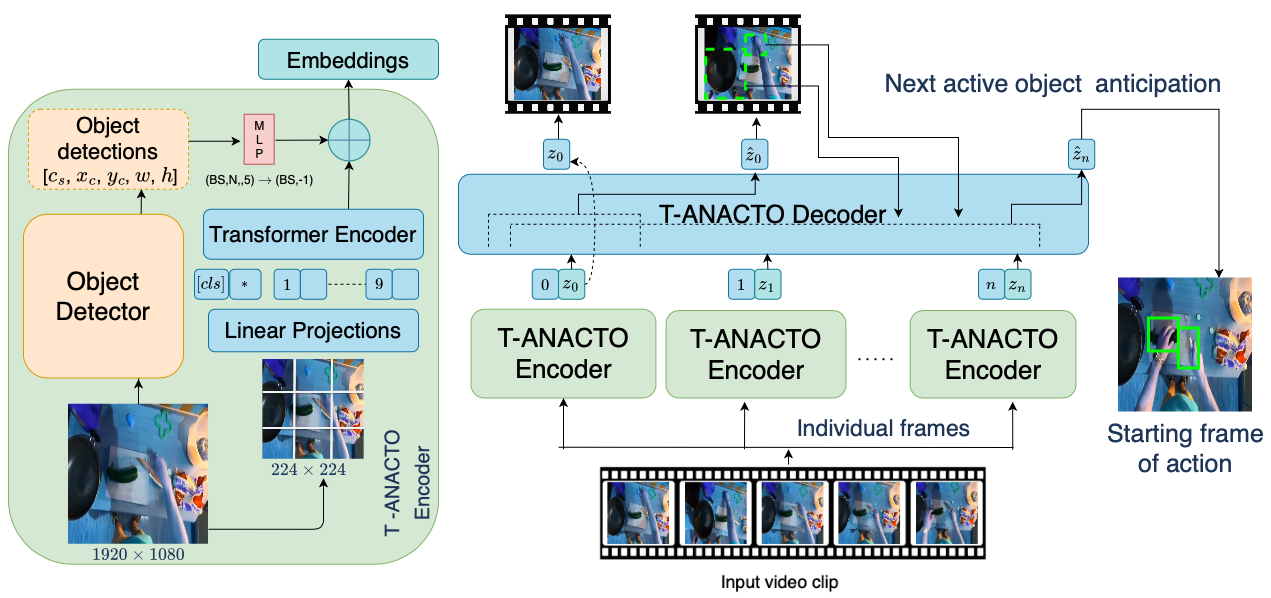
Fig 2. Our T-ANACTO model is an encoder-decoder architecture. Its encoder is composed of
an object detector and a Vision Transformer (ViT). The object detector takes an input frame
(e.g., size of 1920×1080) and predicts the location of objects in terms of bounding boxes (x, y,
w, h) and detection confidence scores (c). ViT takes the resized (224x224) frames as input,
and then divide it into the patches (16×16). The object detections are also
converted to match the scaled size of the frame (i.e., 224×224), reshaped, and are then passed
through a MLP to convert it into the same dimension as the embeddings from the transformer
encoder, which are later concatenated together to be given to the decoder. Transformer decoder uses temporal aggregation to predict the
next active object. For each frame, the decoder aggregate the features from the encoder for current
and past frames along with the embeddings of last predicted active objects and then predicts the
next active object for the future frames.
|